在全球能源結構轉型與“雙碳”目標深入推進的大背景下,新能源產業已成為區域經濟高質量發展的關鍵引擎。江西省依托其獨特的資源稟賦與政策紅利,正全力構建特色鮮明、競爭力強的新能源產業體系。本文結合最新政策與產業數據,獨家繪制2024年江西省新能源產業鏈全景圖譜,并深入剖析計算機軟硬件技術在其間的關鍵賦能作用。
一、 產業政策全景:構筑多維支持體系
江西省新能源產業發展立足于一系列頂層設計與專項政策。省級層面,《江西省“十四五”能源發展規劃》、《江西省新能源汽車產業發展規劃(2023-2027年)》等綱領性文件明確了以光伏、鋰電、新能源汽車為主導,氫能、儲能等為戰略培育方向的發展路徑。各地市亦出臺配套措施,如宜春市聚焦鋰電新能源、上饒市深耕光伏產業,形成了“省級統籌、地市特色”的政策矩陣。政策支持涵蓋財政補貼、稅收優惠、土地保障、人才引進、研發獎勵等多個維度,為產業鏈各環節企業提供了堅實的發展后盾。
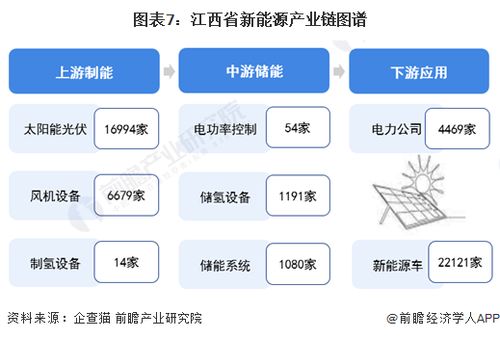
二、 產業鏈現狀圖譜:上下游協同發展
江西省新能源產業鏈已形成相對完整的閉環,并呈現鮮明的區域集聚特征。
- 上游原材料與關鍵部件:以贛州、宜春為核心的稀土永磁材料、鋰礦資源開采與加工基地;以上饒、南昌為重點的光伏硅料、硅片、電池片生產集群。
- 中游核心裝備制造:南昌、九江、贛州等地集聚了光伏組件、鋰離子電池、燃料電池、風電裝備等大批制造企業,產業鏈協同效應初顯。
- 下游應用與運營服務:涵蓋新能源汽車整車制造(如江鈴新能源、吉利在贛項目)、儲能電站建設、充電/加氫基礎設施網絡、光伏電站投資運營等。電池回收與梯次利用環節在政策引導下開始布局,致力于打造綠色循環產業鏈。
三、 產業資源空間布局:“一核引領、多區聯動”
江西省新能源產業空間布局遵循“集群化、差異化”原則,形成了以贛江新區(核心創新平臺)為引領,“贛東北光伏產業帶”、“贛西鋰電產業走廊”、“贛中南新能源汽車及零部件集聚區”等多區域聯動發展的格局。這種布局有效整合了各地的資源、區位與產業基礎優勢,避免了同質化競爭,促進了省內產業協同與互補。
四、 產業鏈發展規劃:邁向高端化、智能化、綠色化
面向江西省新能源產業鏈發展規劃聚焦三大方向:
- 強鏈補鏈延鏈:鞏固提升鋰電、光伏優勢環節,加快補齊氫能制備、儲運、燃料電池系統等短板;延伸發展儲能集成、能源管理服務等高附加值領域。
- 創新驅動發展:依托中科院贛江創新研究院等平臺,攻關固態電池、鈣鈦礦電池、高效光伏材料等前沿技術。
- 深化融合應用:大力推廣“新能源+儲能”、“光儲充一體化”、綠色交通等場景,推動能源生產與消費革命。
五、 計算機軟硬件技術開發的關鍵賦能作用
計算機技術的深度融入是江西新能源產業鏈實現提質增效和智能化升級的核心驅動力。
- 硬件層面:高性能計算集群、工業物聯網傳感器、智能芯片(用于BMS電池管理系統、光伏逆變器控制等)為新能源設備的精準控制、狀態監測與能效優化提供了物理基礎。智能產線與機器人廣泛應用,提升了制造環節的自動化與精密化水平。
- 軟件與算法層面:
- 研發設計:利用CAE仿真軟件、材料計算模擬平臺加速新型電池材料、光伏組件結構的研發進程。
- 生產制造:MES(制造執行系統)、數字孿生工廠實現生產流程的實時監控、優化調度與預測性維護。
- 運營管理:基于大數據與人工智能的能源管理系統(EMS)、智能微電網調控平臺、充電網絡調度系統,顯著提升發電預測精度、電網平衡能力與用戶體驗。
- 安全與運維:AI視覺檢測用于產品缺陷識別,區塊鏈技術助力電池全生命周期溯源,云計算平臺支撐海量設備數據的分析與安全預警。
****
2024年的江西省新能源產業鏈,在清晰的產業圖譜、科學的空間布局與前瞻的發展規劃指引下,正步入發展的快車道。而計算機軟硬件技術的全面滲透與深度融合,如同為這條產業鏈注入了“智慧大腦”與“靈敏神經”,將有力推動江西新能源產業從“制造大省”向“智造強省”和“系統解決方案輸出省”跨越,為中國乃至全球的綠色能源革命貢獻“江西智慧”與“江西方案。